从网络获取数据
你是否已尝试了各种方法,却仍未获得需要的数据?也许有时你在网页上已经找到所需数据了,只是上面并没有下载按钮,复制粘贴功能也用不了。不要着急,这里有一些实用的方法,比如你可以:
-
从基于网页的API接口获得数据,这包括在线数据库提供的用户界面以及各种新式的网络应用(比如Twitter、Facebook等等)。这是获得政府和商业机构数据的好方法,在社交网站上也很有效。
-
从PDF文档提取数据。这很困难,因为PDF是一种针对打印机的格式,里面存储的数据结构和一般文档极为不同。从PDF提取数据比从一本书中提取要困难得多,但还是有一些工具和操作指南可以帮助你完成这项工作。
-
利用有网页抓取功能的网站。在这类网站上,你可以借助其提供的实用工具或是自己写一段建议代码从普通网页上提取结构化的内容。这种方法十分强大,适用于许多情况,但这要求你了解一些关于网页的知识。
借助这些强大科技功能的同时,也别忘了简单易用的方法:花点时间搜索机器可读的数据,或者给持有所需数据的机构打电话都可能会帮助你拿到你想要的数据。
在本节我们将展示一则从HTML网页上极为简单的抓取范例。
什么是机器可读的数据?
大多数方法的目的都是为了获得机器可读的数据。机器可读的数据是为方便计算机处理而生成的,而不是为了向人类用户展示。这些数据的结构与其内容相关,但与数据的最终展示形式不同。简单的机器可读数据格式包括CSV、XML、JSON和Excel文档等等,而Word文档、HTML网页和PDF文档则更侧重于数据在视觉上的呈现。PDF是一种与打印机交互的语言,它记录的信息并不是一个个字母,而是线与点在页面上的位置。
从网页上抓取什么?
这种事情每个人都做过:你在某网站上浏览时发现一个有趣的表格,想把它复制到Excel中便于计算或是存储下来。但有时这种方法并不奏效,有时你所需要的数据又分布在好几个网站的页面上。手动复制粘贴太乏味了,而用一些小代码可以令你事半功倍。
网页抓取的一大优势是其几乎可以用于所有网站,无论是天气预报还是政府预算。即便该网站并未提供针对原始数据访问的API接口,你同样可以抓取。
网页抓取的局限性
抓取不是万能的,也会遇到障碍。网页难以抓取的主要因素有:
-
HTML编码拙劣,结构信息很少或者压根没有,常见于早期的政府网站。
-
网站有防止机器自动访问的验证系统,如CAPTCHA验证码和付费系统。
-
使用浏览器Cookies存储用户信息获得用户动作再给出内容的会话系统。
-
网站未提供完整的分类列表和通配符搜索功能。
-
服务器管理员对大量访问做出了限制。
另一方面,法律限制也会成为障碍。部分国际承认关于数据库的权利,这会限制你重复利用在网络上公开发表的信息。有的时候,你可以无视这些法律条款仍然进行抓取,这取决你所在地的司法管辖权,如果你是记者的话也会有一些特殊的便利。抓取免费的政府数据一般没事,不过在发表之前还是应当再查一遍。商业组织和部分NGO对数据抓取行为采取几乎零容忍的态度,他们会指控你“破坏”他们的系统。其他可能侵犯个人隐私的数据则会触犯数据隐私法令,也与职业道德相背。
抓取工具
有许多程序可用于从网站提取大量信息,包括浏览器扩展程序和一些网络服务。Readability(从网页上抓取正文)和DownThemAll(批量下载文件)工具可以在部分浏览器上自动处理繁琐的任务,Chrome浏览器的Scraper插件可以从网站上提取表格。针对开发者的扩展程序FireBug(针对Firefox浏览器,Chrome、Safari和IE已内置类似功能)可以让你清晰了解网站结构和浏览器与服务器之间的通讯。
ScraperWiki网站提供包括Python、Ruby、PHP在内的多种语言供用户自行编写抓取代码。这使得用户不再需要在本地安装语言环境便可编码进行抓取工作。另外Google电子表格和Yahoo! Pipes等网页服务也提供从其他网站提取内容的服务。
网页抓取工具如何运作?
网络抓取工具通常是用Python、Ruby或PHP写成了一小段程序代码。具体选择哪一种语言取决于你的周围,如果你的新闻机构或者同城市的同行中有人已开始用某种语言进行编写,你最好也采用同样的语言。
虽然前文提到的点击选择工具可以帮助你上手,但真正复杂的步骤是确定正确的页面和页面上存储所需信息的正确元素。这些步骤的关键并不在于编程,而在于对网站和数据库结构的了解。
浏览器在展现网页时主要运用以下两种技术:通过HTTP协议与服务器通讯,请求获得文档、图片、视频等指定资源;然后获得以HTML编码写成的网页内容。
网页的构造
每个HTML网页都是由有一定结构层次的“盒子”构造的(由HTML“标签”定义)。大的“盒子”中又会包含小的“盒子”,就像一个表格中有行、列和单元格一样。不同的标签有不同的功能,可以定义“盒子”、表格、图片或者是超级链接。标签也有附加属性(比如唯一标识符),并可被定义在“类”中,这便于我们定位和获取文档中的独立元素。编写抓取工具的核心就是选择合适的元素从而获取对应的内容。
查看网页元素时,所有代码都可按照“盒子”进行分割。
在开始抓取网页之前,你需要了解HTML文档中会出现哪些类型的元素。举例来说,<table>会形成一个表格,在其中<tr>定义了行,<td>又把行细分为单元格。最常见的元素类型是<div>,简单来说它可以定义任何内容区域。认知这些元素最简单的方法就是利用浏览器上的开发者工具,在将鼠标悬停在网页的特定区域上时,这些工具就会自动显示该区域对应的代码。
标签就像书的封面一样,告诉你哪里是开头,哪里是结尾。<em>表示文字从此处开始以斜体显示_,</em>则标明斜体字到此结束。多简单!
例子:使用Python抓取核事件
国际原子能机构(IAEA)门户网站上的新闻栏目下记录了全球各地的放射性事故(栏目名正申请加入“怪异标题俱乐部”)。该网页使用简单、类似博客形式的结构,便于抓取。
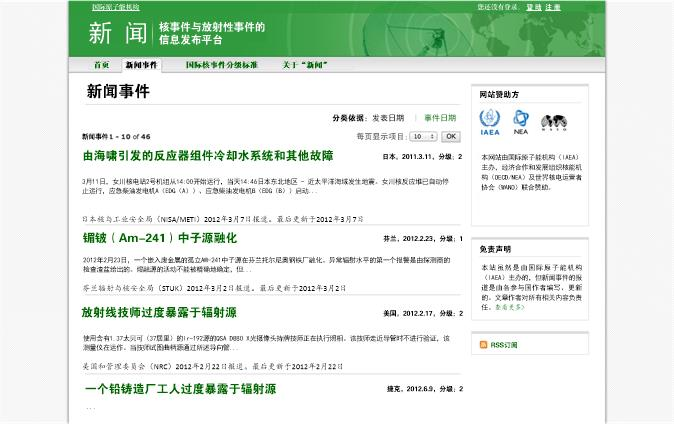
首先,在ScraperWiki上新建一个Python抓取工具,然后你将看到一个基本空白的文本框,里面有些基本的框架代码。同时在另一个窗口中打开IAEA网站,并打开浏览器的开发者工具。在“元素”视图下,找到每条新闻标题所对应的HTML元素,开发者工具会明确指出定义标题的代码。
进一步观察可以发现,标题用<h4>+定义在<table>+中。每个事件都有一个单独的+<tr>+行,里面还有事件描述和日期。为了获取所有事件的标题,我们应当用一定的方法按顺序选择表格中每一行,然后获得标题元素中的文本。
要将这些进程写成代码,我们需要明确具体的步骤。我们先玩个小游戏感受一下什么是步骤。在ScraperWiki的界面中,先尝试为自己写一些指引,你要通过代码完成哪些工作,就像食谱中的工序一样(每行开始前写一个“#”以告诉Python这行不是计算机代码)。例如:
# 寻找表格中的所有行
# 不要让独角兽在左侧溢出(注:IT冷笑话)写的时候要尽可能准确,不要认为程序真的懂你要抓取哪些内容。
写了几行伪代码后,我们再来看看真正代码的前几行吧:
import scraperwiki
from lxml import html在第一段中,我们从库(预先写好的代码片段)中调用了已经存在的功能,ScraperWiki在此段代码中已经提供了下载网站的功能,+lxml+则是一个用来对HTML文档进行结构分析的工具。告诉你个好消息,在ScraperWiki中写Python的抓取工具,前两行都是一样的。
url = "http://www-news.iaea.org/EventList.aspx"
doc_text = scraperwiki.scrape(url)
doc = html.fromstring(doc_text)然后,代码定义了变量名称:url,其值为IAEA的网页地址。这行告诉抓取工具,有这么个事情,我们要对他做些动作。注意这段URL网址在引号中,表明这不是一段代码,而是一个_字符串_,一串字符序列。
然后我们将这段URL变量放入一个指令,scraperwiki.scrape。这段指令会执行已定义好的动作:下载网页。这段工作完成后,它将执行指令将内容输出到另一个变量doc_text中,然后在doc_text中存储的就是网页的文本了。不过这段文本并不是你在浏览器中看到的样子,它是以源代码形式存储的,包含了所有的标签。由于这些代码不容易解析,我们再用另一个指令html.fromstring生成一个特殊的格式,方便我们分析其中元素,这种格式叫做文档对象模型(DOM)。
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title最后一步,我们使用DOM搜索表格中的每一行,并获取事件的头部获取标题。这里有两个新感念:for循环和元素选择器(.cssselect)。for循环的工作很简单,它会遍历项目清单,给每个项目分配一个别名(在本段中就是每行+row+),然后对每个项目都执行一次缩进部分的指令。
另一个概念——元素选择器,指的是利用特定语言在文档中查找元素。CSS选择器通常被用来在HTML元素上添加布局信息,我们可以利用它在页面中精确的定位元素。在本段代码的第6行,我们使用#tblEvents tr选出<tr>标签中所有选择器ID为tblEvents的行(ID前需加“#”作为标识)。这段代码将会返回符合条件的<tr>元素列表。
接着在第7行,我们使用另一个选择器查找<h4>标签(标题)中的<a>标签(超级链接)。这里我们一次只找出一个元素(因为一行中只有一个标题),所以在找到后我们需要通过.pop()命令将其输出。
请注意,DOM中的某些元素含有实际的文本,也就是非程序语言的文本。对于这些文本,我们在第8行使用[element].text命令。最后,在第9行,我们将结果输出至ScraperWiki的控制台。完成后,只需在抓取工具中点击“运行”,小窗口上便会一一列出IAEA网站上的事件名称了。
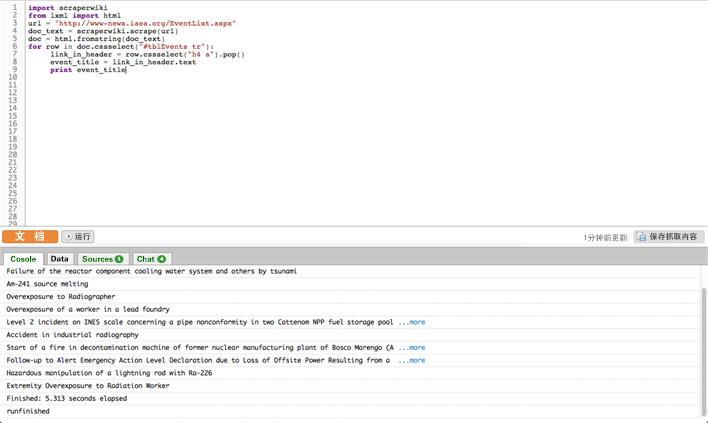
现在一个基础的抓取工具就开始运行了。它将下载网页,将其转换为DOM格式,然后你就可以从中选择、获取特定内容了。在这个框架下,你可以试着利用ScraperWiki和Python的帮助文档解决剩下的问题:
-
你能找到每个事件标题中的超级链接地址吗?
-
你能利用CSS类名选择包含日期和时间的小“盒子”并将其中文本输出吗?
-
ScraperWiki为每个抓取工具分配了一个小的数据库用于存储结果,请从文档中复制相关事例,将获取到的事件标题、超级链接和日期存储在一起。
-
事件列表不止一页,你能让抓取工具翻页获得之前的事件信息吗?
在尝试解决这些问题的同时,你也可以在ScraperWiki上逛逛。网站上很多现成抓取工具中都有实用的案例,其中的数据也很有用。这样你就不需要从头开始敲代码了,利用类似的案例,对代码进行改动,再部署到自己的问题上就可以了。
— 弗里德瑞克·林登伯格(Friedrich Lindenberg),开放知识基金会